Exploring the Swedish Kelly List Dataset
September 26, 2022
Last week, I contributed the Swedish Kelly list dataset to the Hugging Face Hub. Since then, I’ve been brainstorming ideas for a project to create with it.
About the Swedish Kelly List
The Swedish Kelly list is a frequency-based vocabulary list of 8,425 general-purpose Swedish words created by Språkbanken Text at the University of Gothenburg. It was generated from SweWaC, a 114 million-word web-acquired corpus, and its lemmas cover 80% of SweWaC. The Swedish Kelly list was created as a resource for language learners, and each lemma is annotated with a CEFR level. CEFR (The Common European Framework of Reference for Languages) is a standard for measuring language proficiency. It has six levels ranging from familiarity with everyday expressions and basic phrases (level A1) to understanding virtually everything you hear or read easily (level C2). Lemmas in the Swedish Kelly list are equally distributed across CEFR levels: there are 1404 A1, A2, B1, B2, and C1 lemmas and 1405 C2 lemmas.
A Possible Application
One of the applications suggested by the dataset’s creators is a program that evaluates whether a Swedish text is appropriate for a learner based on their proficiency. Building such a program didn’t sound fun, but I was curious about what it might entail. I wanted my program to consider the general readability of a text and readability specific to a learner’s proficiency, so I started by researching existing readability formulas for Swedish text.
Läsbarhetsindex (LIX)
The most common readability formula for Swedish text is LIX, an abbreviation of läsbarhetsindex (“readability index” in English). LIX generates a readability score based on the average number of words in sentences and the percentage of long words (defined as words longer than six letters). The higher the LIX score, the greater the complexity of the text.
LIX = (number of words ÷ number of sentences) + 100(number of long words ÷ number of words)
Since word length accounts for half of a LIX score, I wondered whether there was a correlation between length and CEFR level for lemmas in the Swedish Kelly list. I hypothesized that A1 lemmas would generally be shorter than C2 lemmas.
Exploring the Dataset
To test my hypothesis, I plotted the lemmas by their IDs and their length. IDs start at one and correspond to a lemma’s rank. For example, the lemma with an ID of 500 is the 500th most frequent lemma in the dataset. Additionally, the higher the frequency of a lemma, the more likely it is to be a beginner-level word.
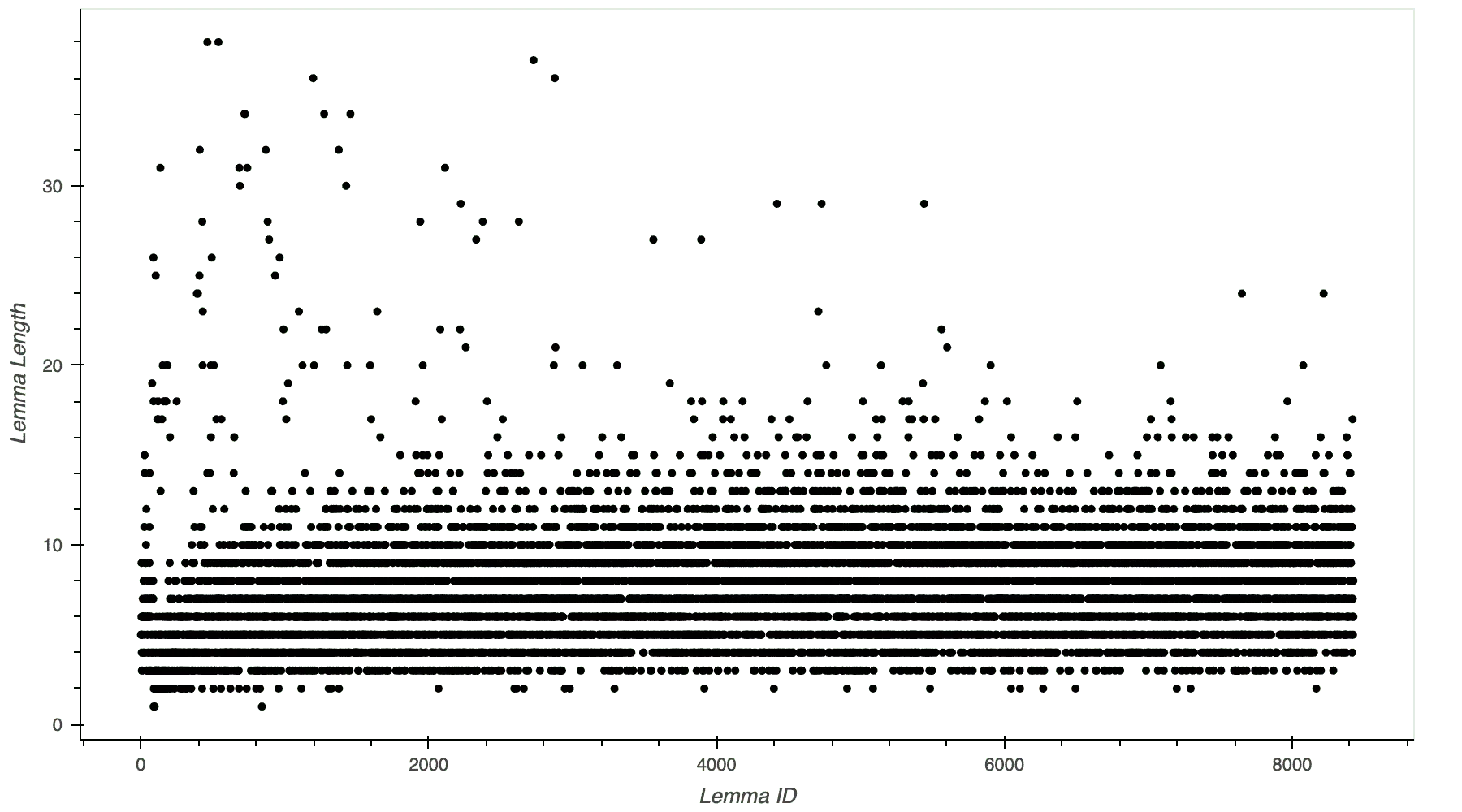
Variation by CEFR Level
Since I was interested in how length varied by CEFR level, not just by rank, I colored each lemma’s marker according to the lemma’s CEFR level.
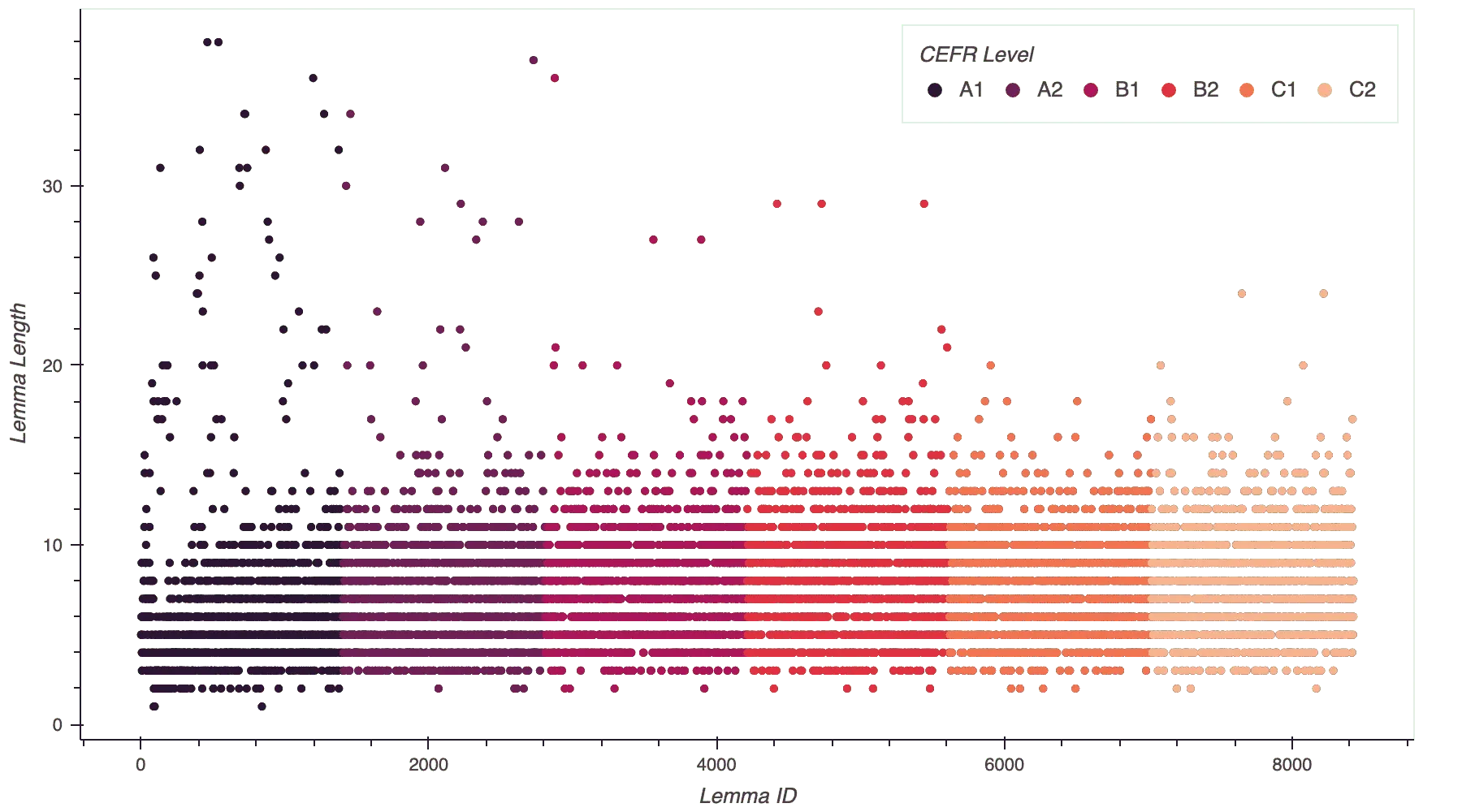
As I hypothesized, A1 lemmas were shorter than C2 lemmas. A1 lemmas had a mean length of 6.44 and a median length of five, while C2 lemmas had a mean length of 7.97 and a median length of eight. As expected, there were more two and three-letter lemmas at the A1 level than at the C2 level. But, surprisingly, way more A1 lemmas than C2 lemmas were longer than 20 letters. Additionally, the max length of A1 lemmas was 38, whereas the max length of C2 lemmas was 24.
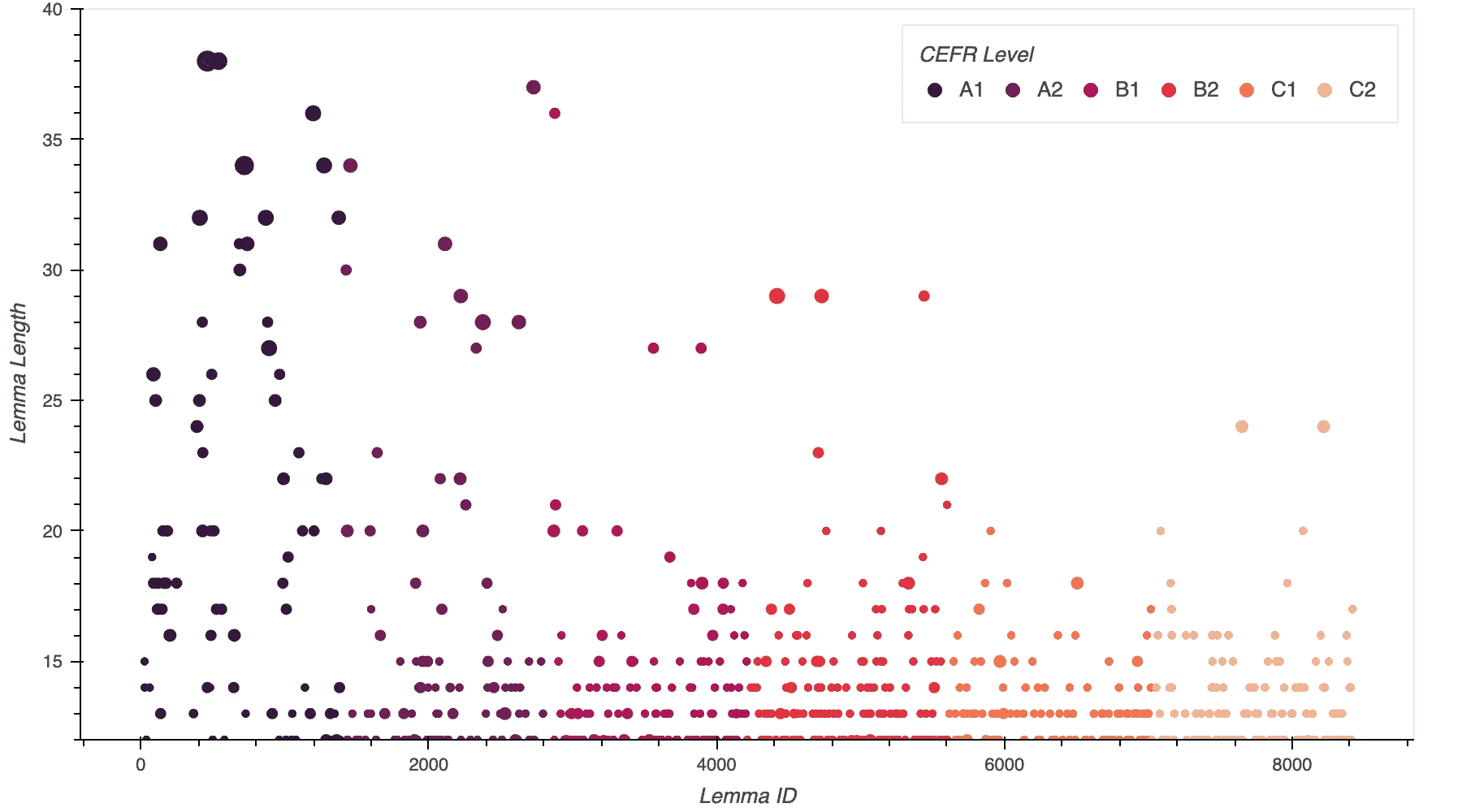
Sampling Lemmas Longer Than 12 Letters
The data points were sparser and more varied for lemmas longer than 12 letters, so I sampled A1 and C2 lemmas longer than 12 and manually inspected them. There were 72 A1 lemmas and 74 C2 lemmas that fit this criterion. What stood out was that some A1 lemma entries included both a lemma and its alternative spellings. In contrast, all C2 lemma entries I sampled contained only one word. (The dataset’s documentation mentions that lemmas are sometimes provided with their spelling or stylistic variants, but I forgot this. 🙃)
| id | cefr_level | lemma | lemma_length |
|---|---|---|---|
| 26 | A1 | inrikesminister | 15 |
| 27 | A1 | inrikespolitik | 14 |
| 61 | A1 | Storbritannien | 14 |
| 78 | A1 | utbildningsminister | 19 |
| 87 | A1 | och (vardagl. å; förk. o.) | 26 |
| 88 | A1 | vara (vardagl. va) | 18 |
| 103 | A1 | inte (formellt: icke, ej) | 25 |
| 115 | A1 | de (vardagl. dom) | 17 |
| 119 | A1 | sig (vardagl. sej) | 18 |
| 135 | A1 | någon (vardagl. nån, förk. ngn) | 31 |
| id | cefr_level | lemma | lemma_length |
|---|---|---|---|
| 7054 | C2 | funktionalitet | 14 |
| 7066 | C2 | revolutionerande | 16 |
| 7080 | C2 | specifikation | 13 |
| 7085 | C2 | internationalisering | 20 |
| 7147 | C2 | specialisering | 14 |
| 7155 | C2 | styrelseordförande | 18 |
| 7161 | C2 | telekommunikation | 17 |
| 7162 | C2 | karakteristisk | 14 |
| 7163 | C2 | åklagarmyndighet | 16 |
| 7182 | C2 | samstämmighet | 13 |
Variation by Number of Words per Lemma
Since I was now interested in the number of words in a word’s lemma entry, I resized each lemma’s marker correspondingly. It turned out that most A1 lemmas longer than 12 letters contained more than one word.
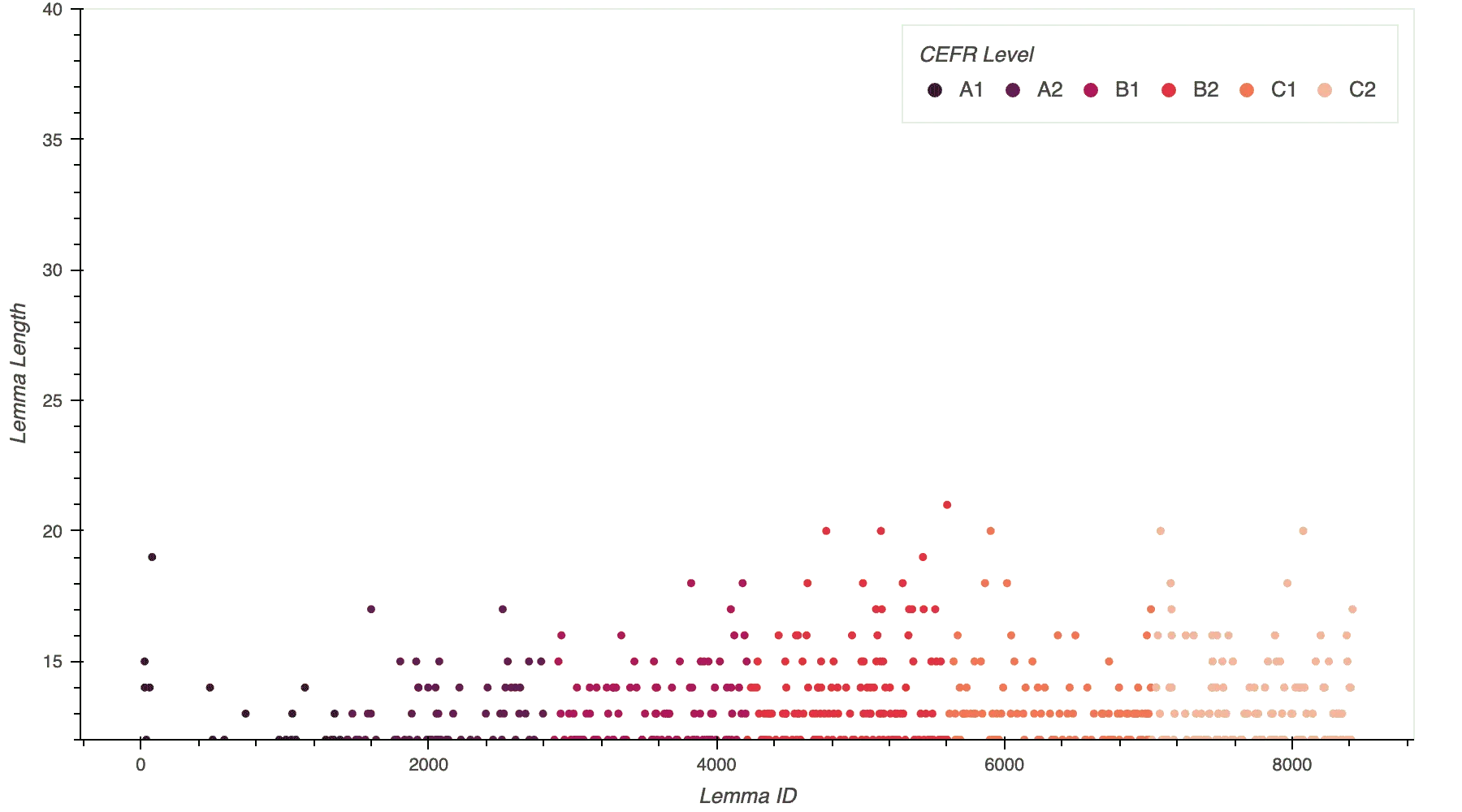
When I excluded multiword lemmas from the plot, there were far more C2 lemmas (72) than A1 lemmas (nine).
| id | cefr_level | lemma | lemma_length |
|---|---|---|---|
| 26 | A1 | inrikesminister | 15 |
| 27 | A1 | inrikespolitik | 14 |
| 61 | A1 | Storbritannien | 14 |
| 78 | A1 | utbildningsminister | 19 |
| 480 | A1 | internationell | 14 |
| 728 | A1 | förutsättning | 13 |
| 1052 | A1 | grundläggande | 13 |
| 1140 | A1 | antingen…eller | 14 |
| 1346 | A1 | arbetsmarknad | 13 |
What’s Next?
I plan to continue exploring the Swedish Kelly list dataset. Now, rather than brainstorming what to build with the dataset, I’m considering ways to extend it. The first item on my list is creating a new field for lemmas’ spelling and stylistic variants.
Resources
- View the dataset on the Hugging Face Hub
- Swedish Kelly list dataset source code
- Companion notebook for this blog post
- Common European Framework of Reference for Languages (CEFR) Levels
- The Lix and Rix readability formulas
- LIX calculator (på svenska 🇸🇪)
If you enjoyed the read, check out another post or subscribe to the RSS feed.